This project was done at the University of Nevada, Las Vegas, under the guidance of Professor Kang in computer science.
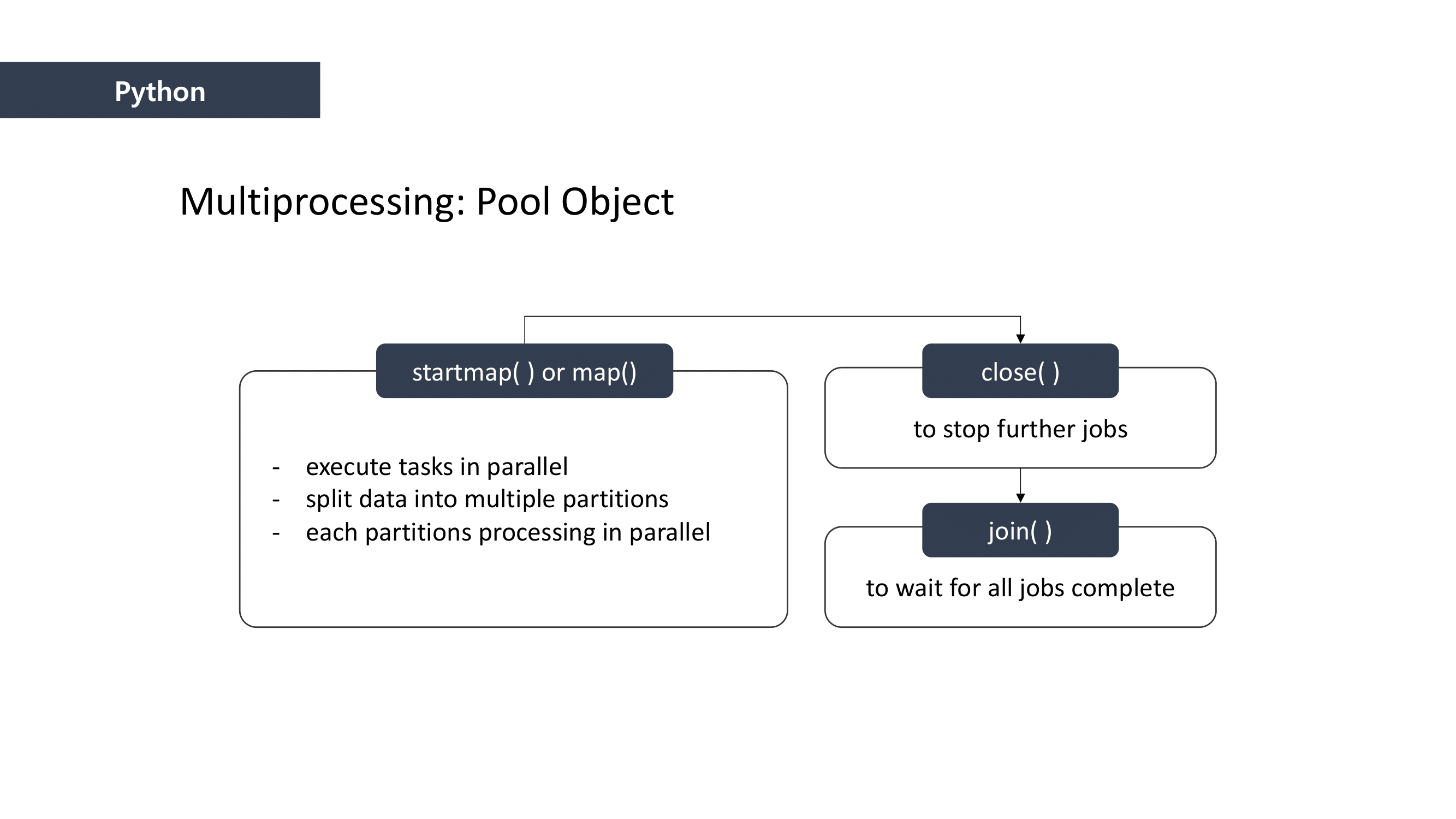
Scalable Data Processing with MapReduce


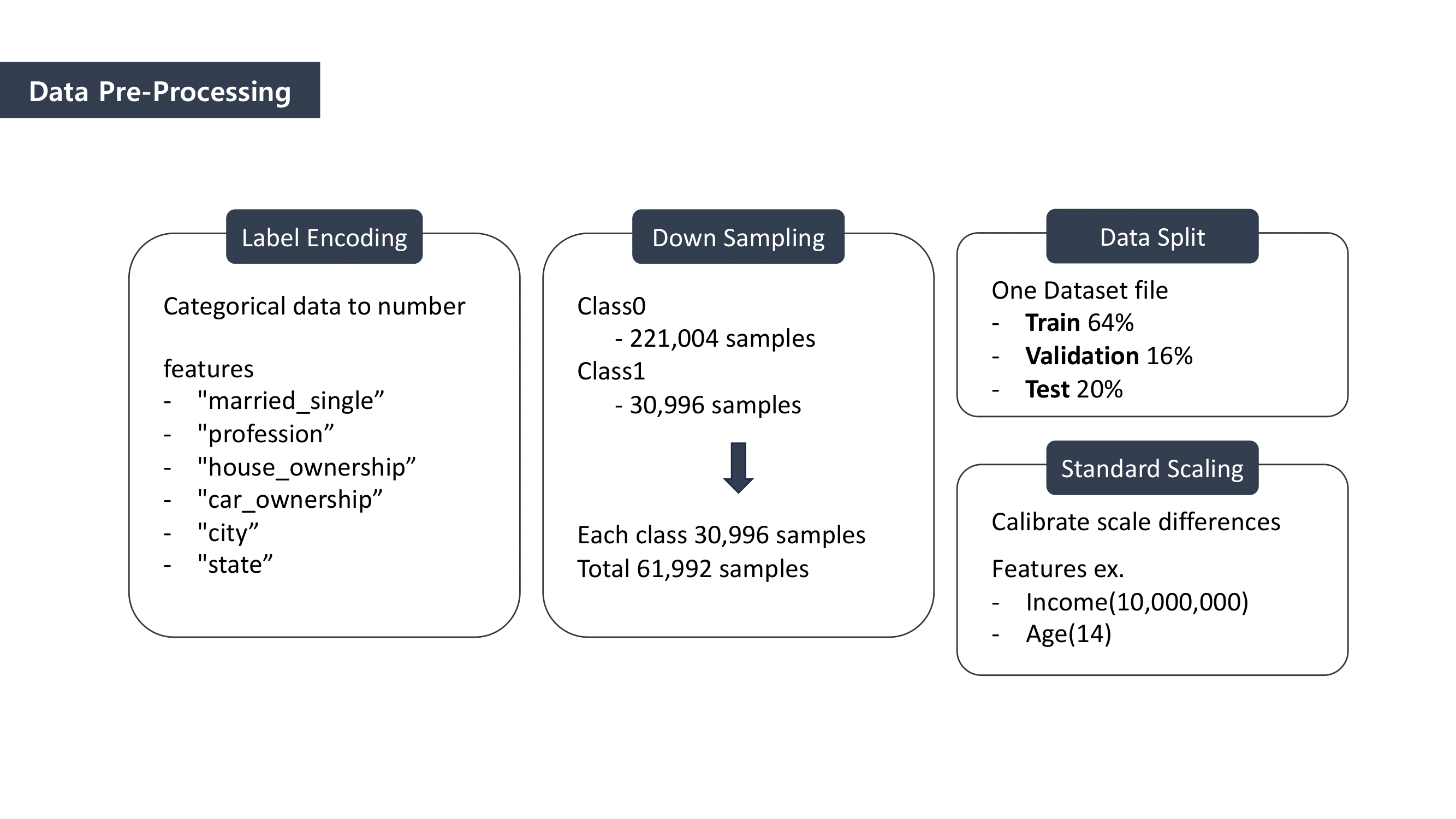
We used this data from Kaggle, it was composed of user factors and their final states whether a user was at risk of defaulting on a bank loan.
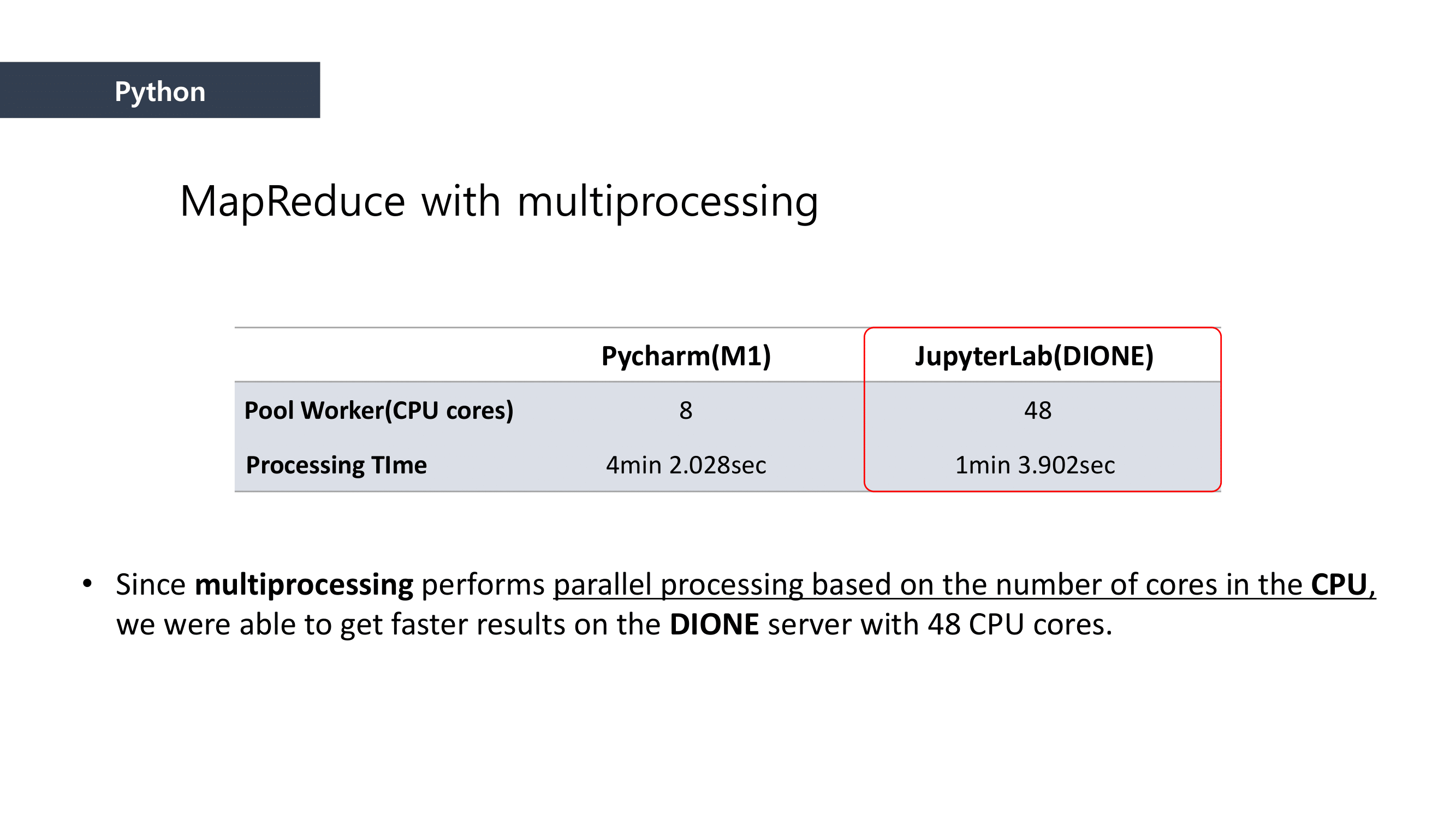
- It was literally “Big-data”, becasue it contains 252,000 rows!!
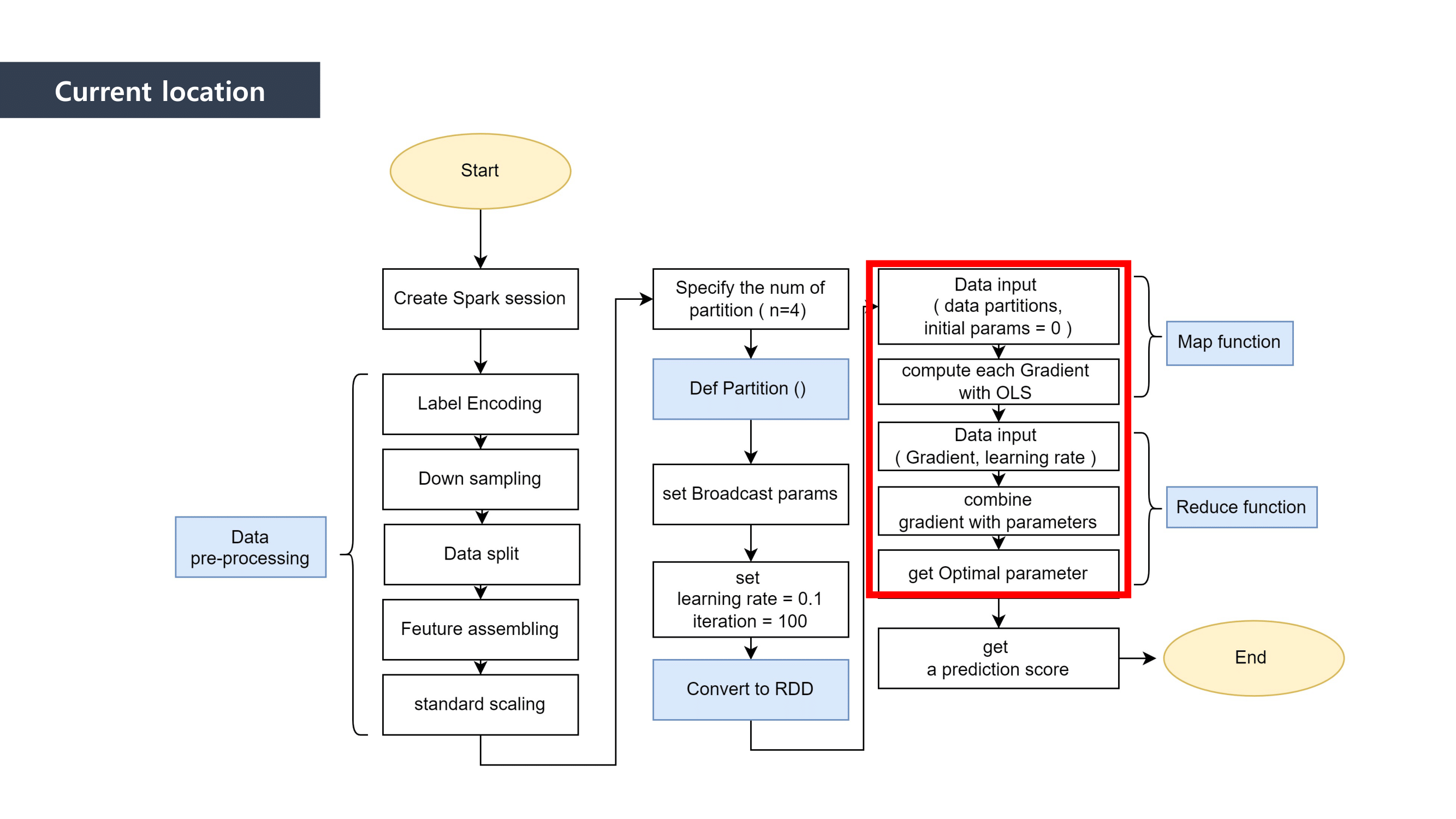
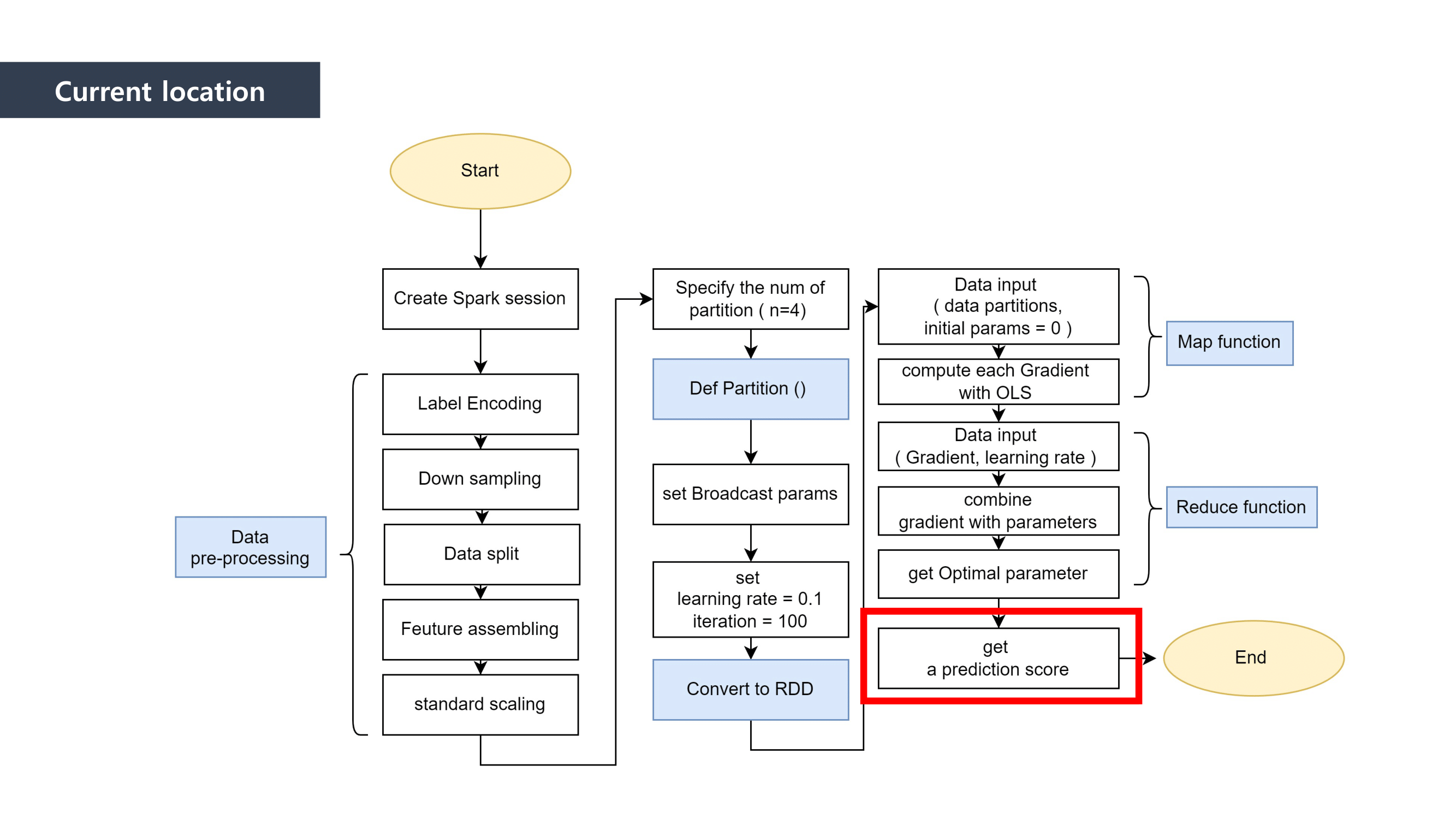
- Must to use a Parallel Processing method called “MapReduce”
BUT !! In this project, Data was not a matter,
it was chosen for its SIZE to practice applying MapReduce!!

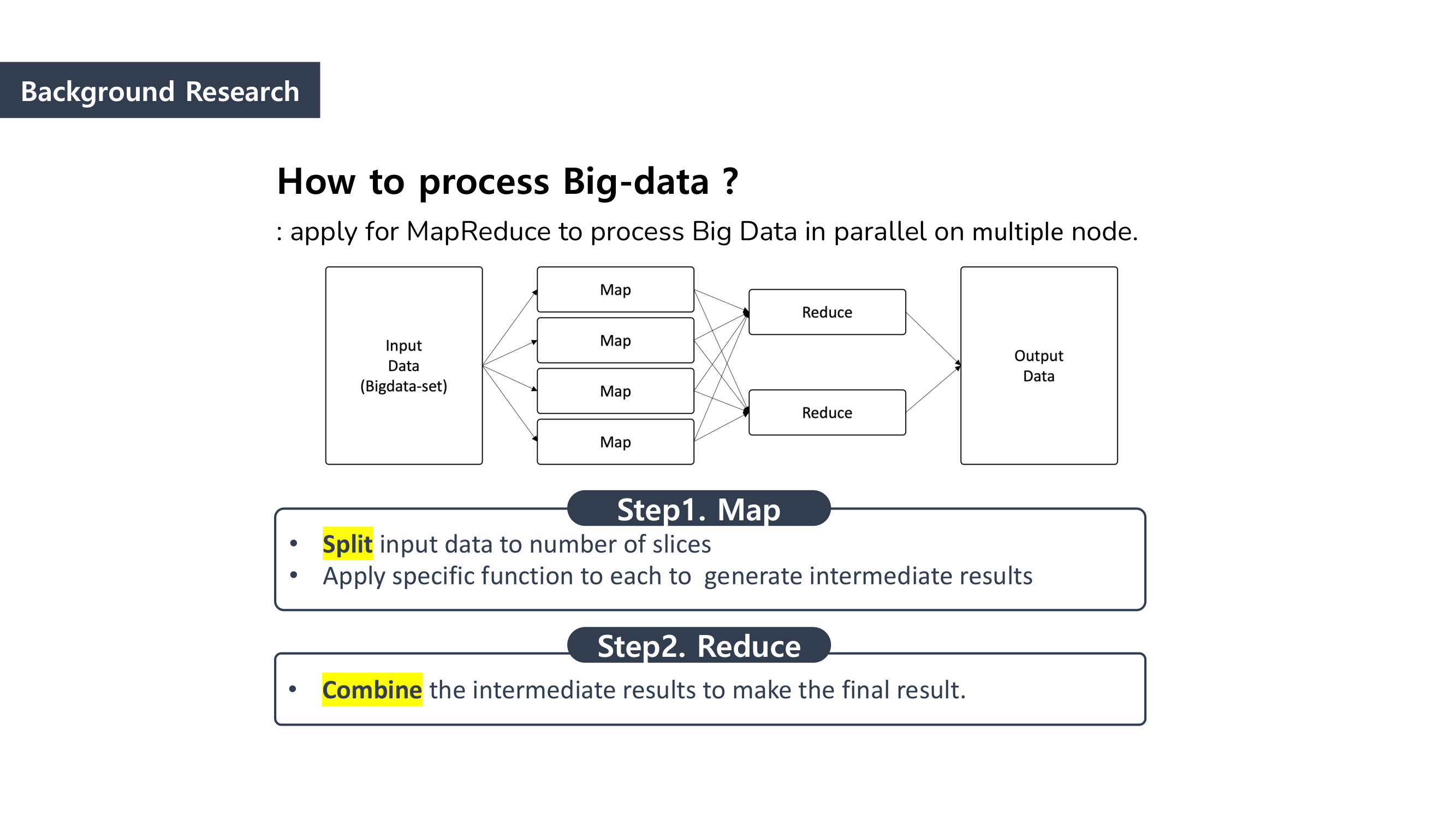
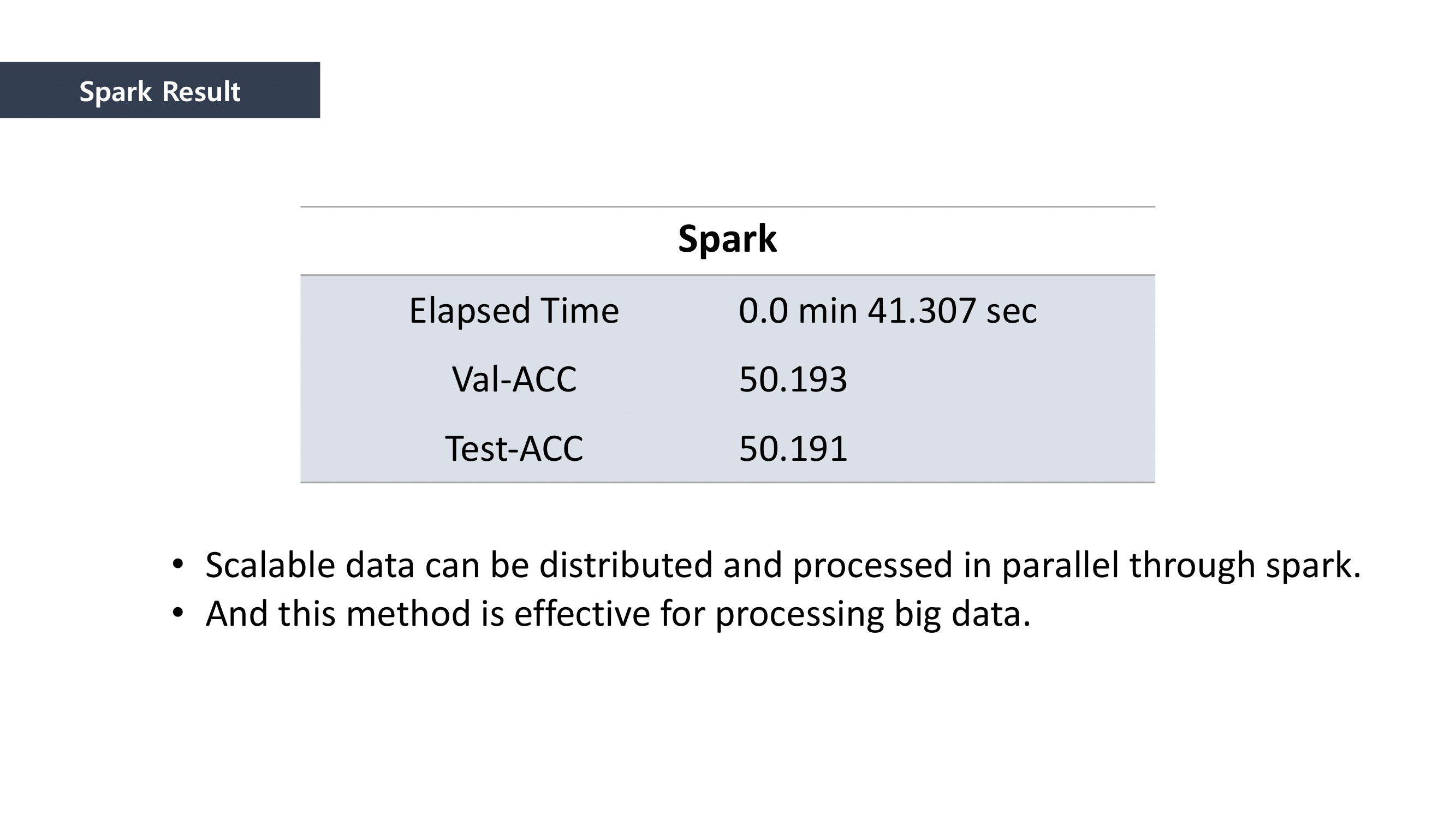
Rather than the data itself, we focused on how efficiently we processed big data.
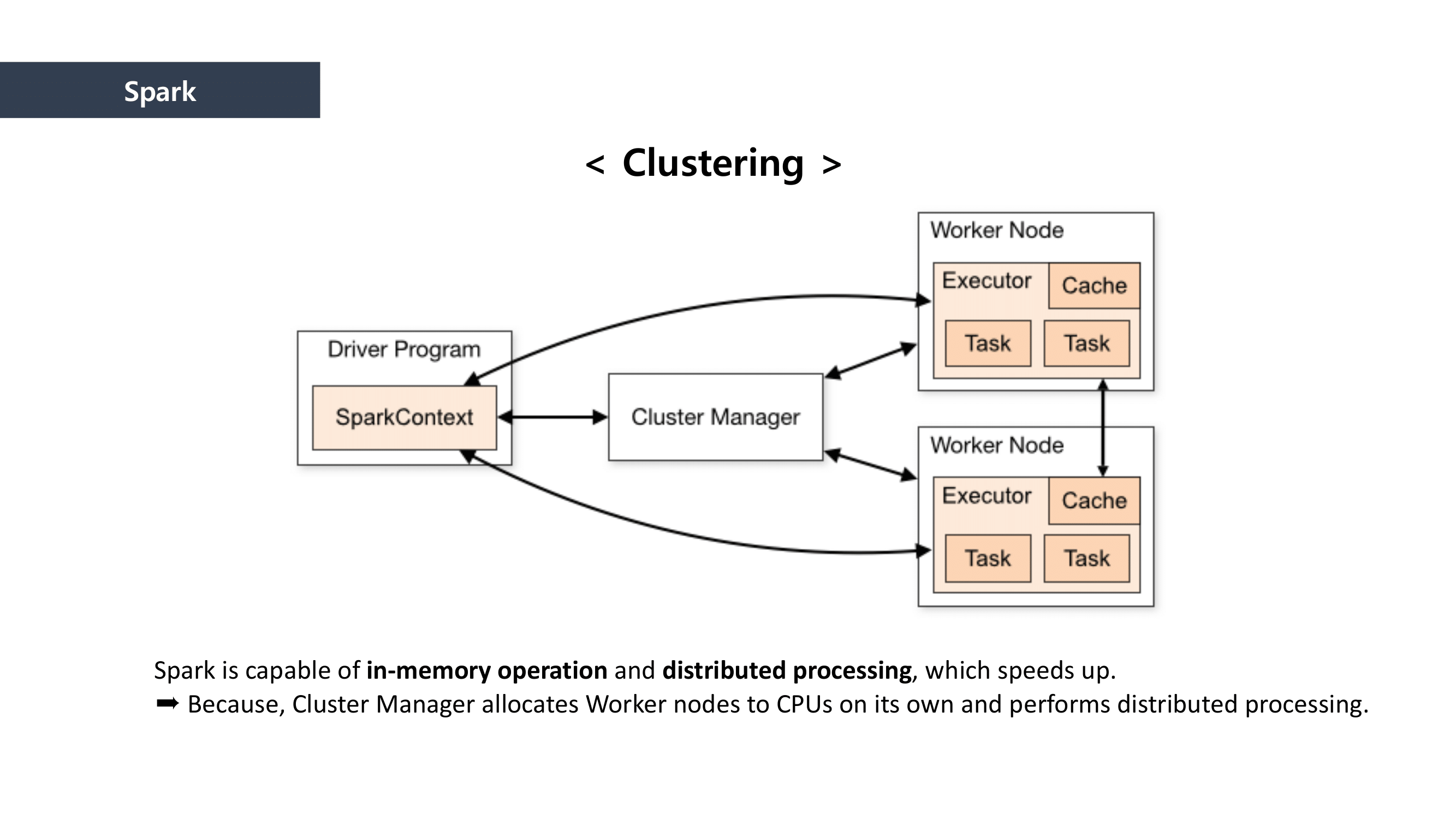
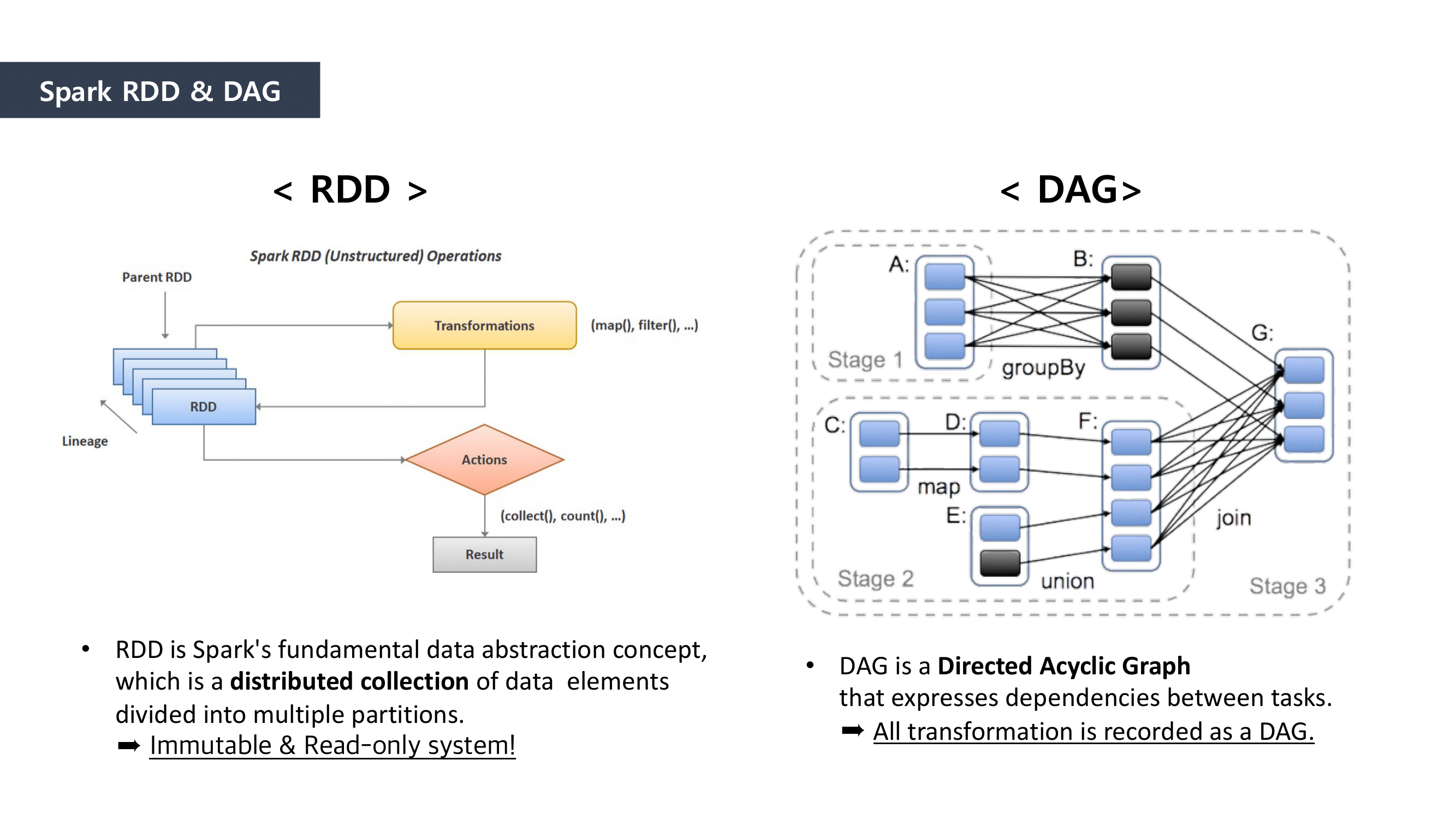
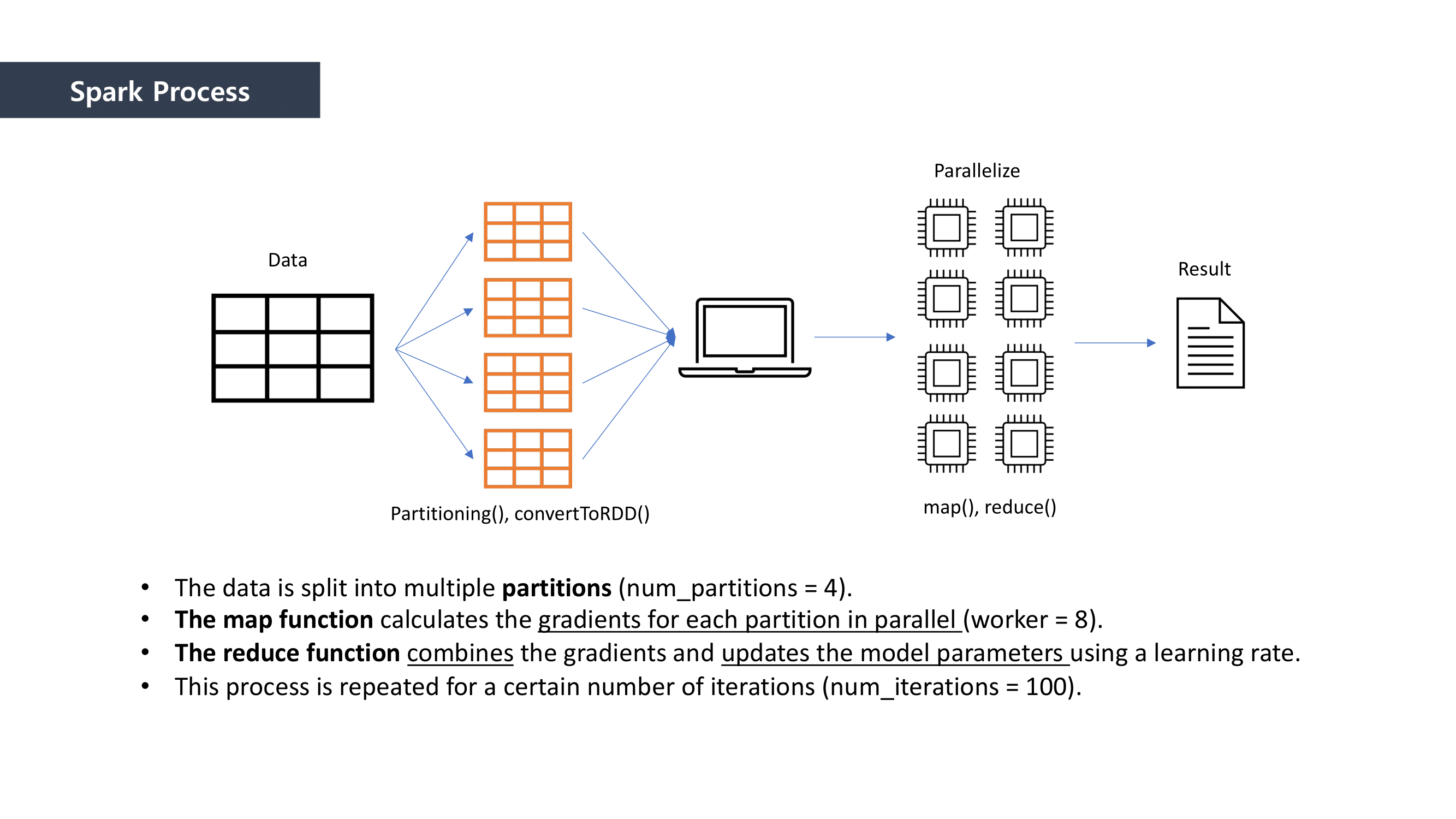
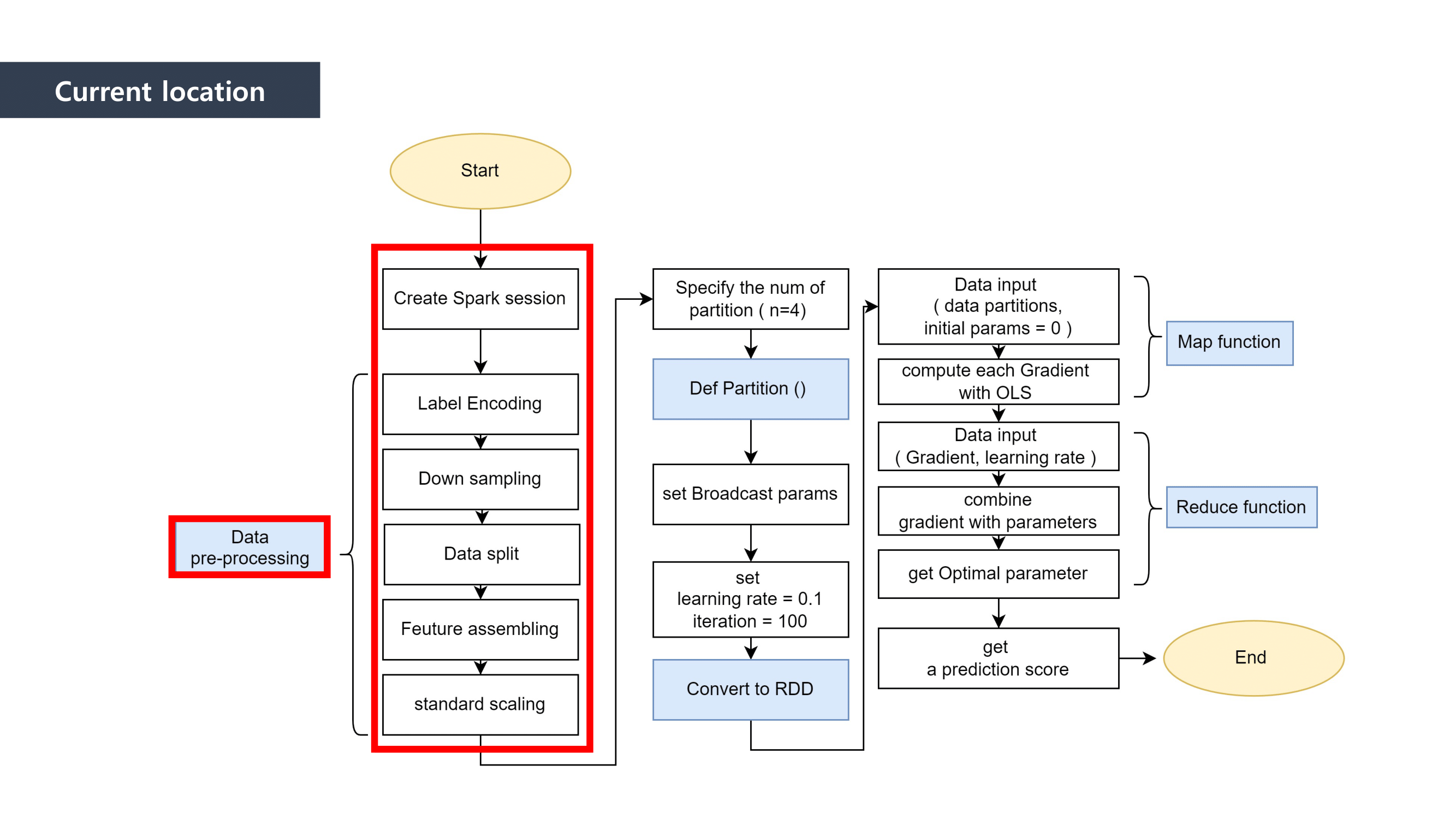
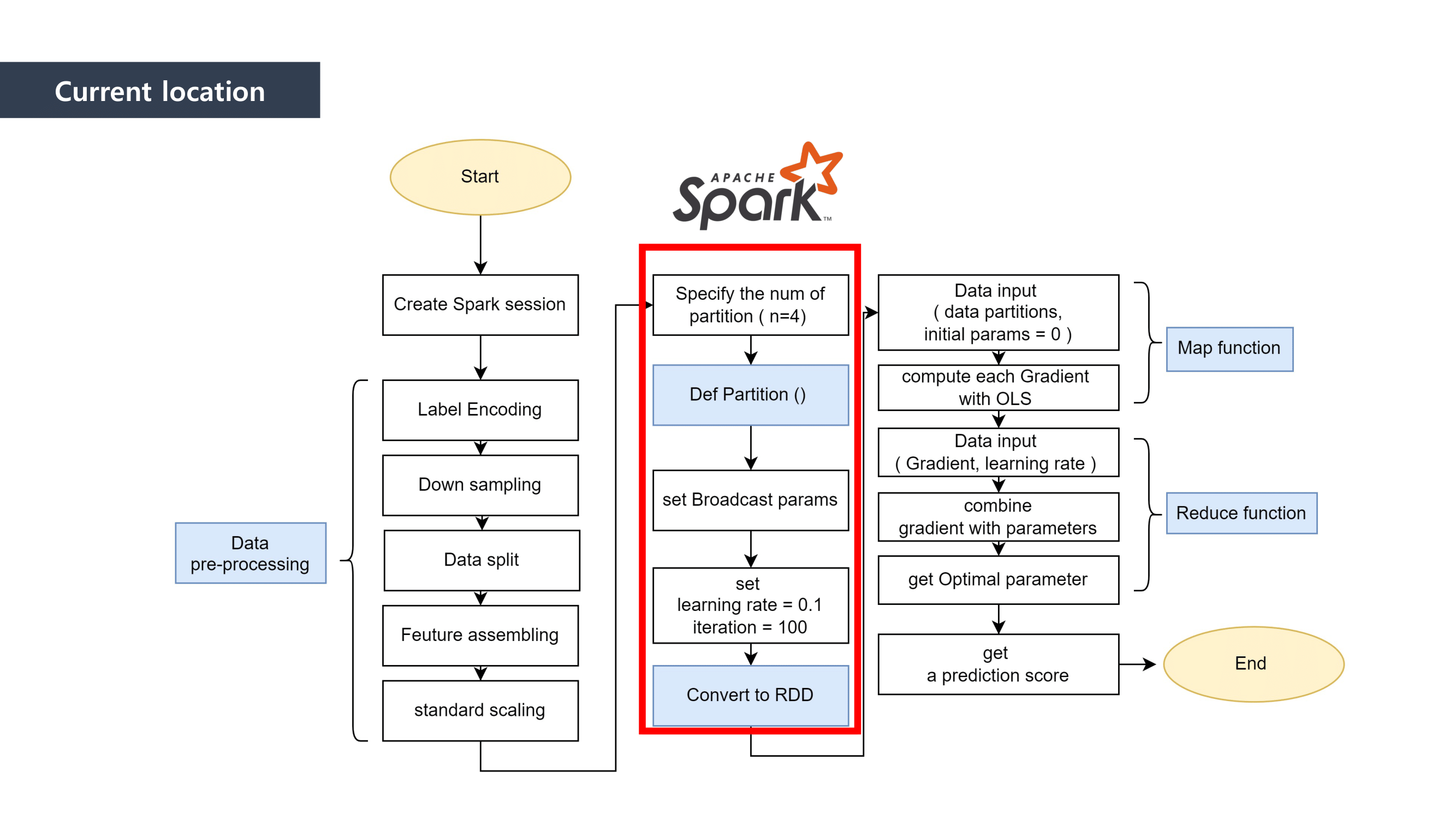
MapReduce is the way to dramatically increase the efficiency of processing large scale datasets through distributed parallelism.
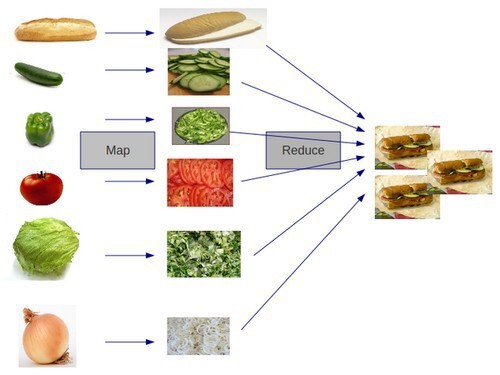
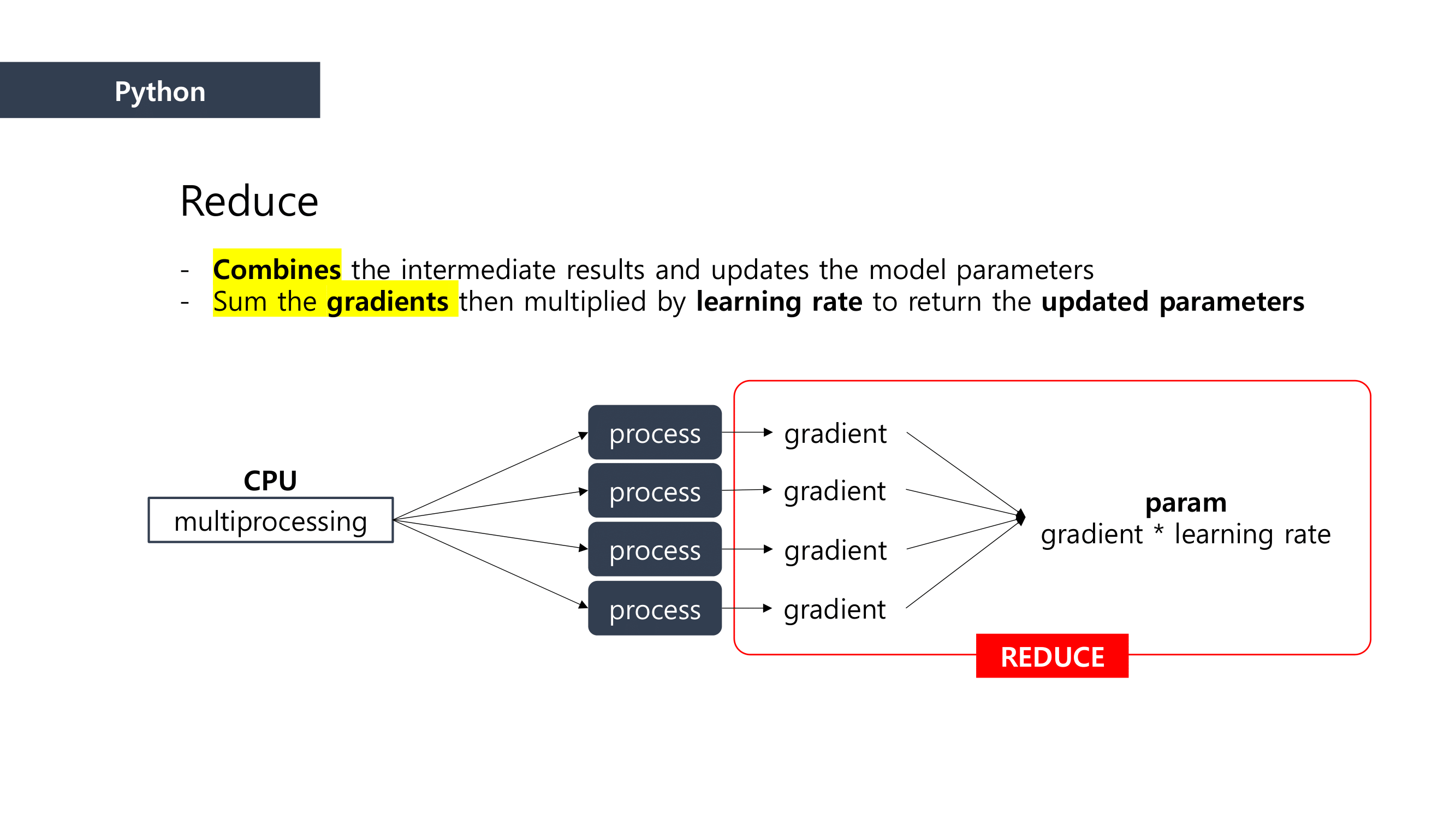
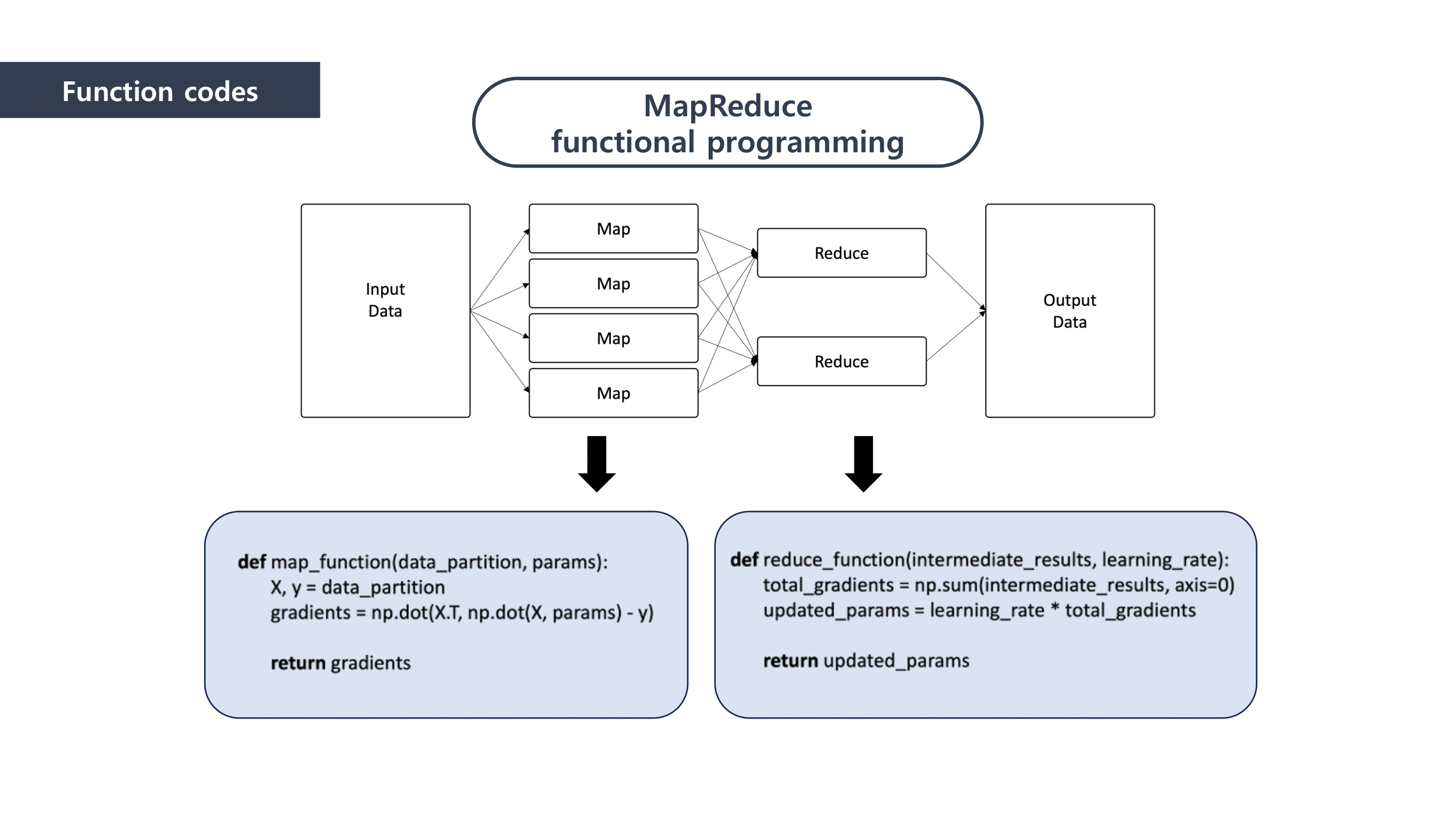
It is composed of “Map” and “Reduce” parts.
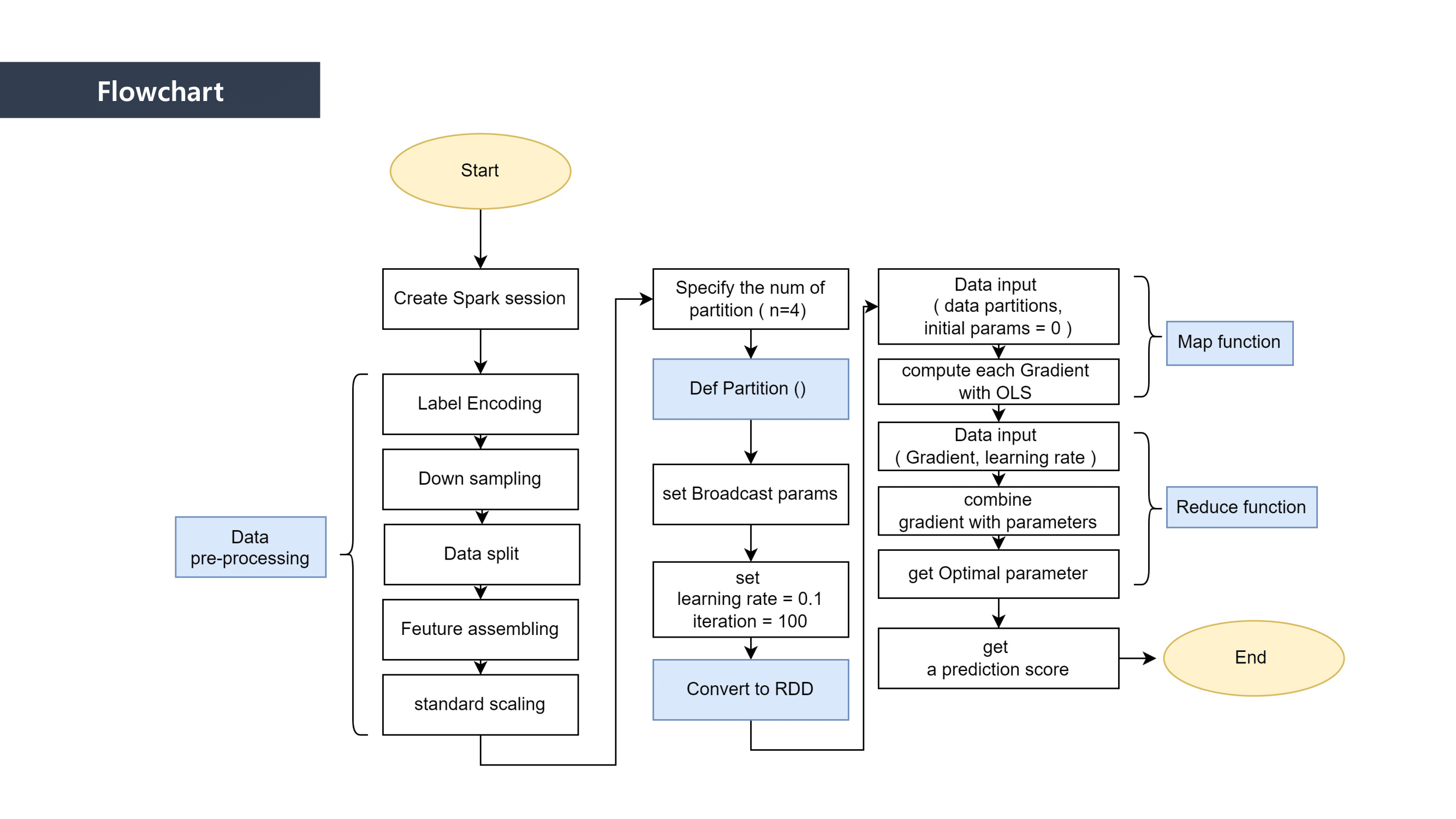
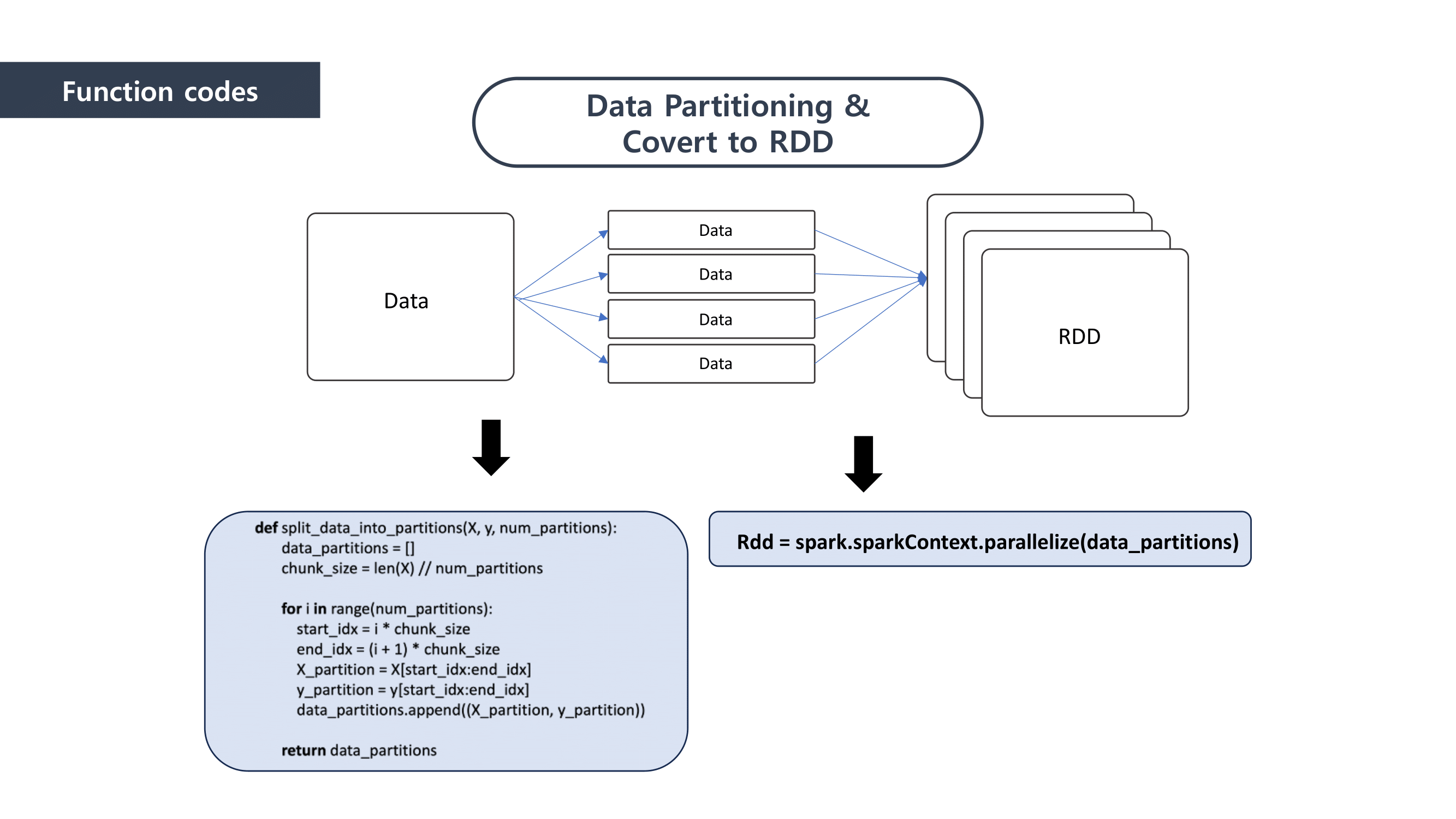
First, when it comes to “Map” part, we separated the data and mapped the data that can be paired together. And then we “reduced” the data size by summing the mapped data.
This is how MapReduce works.

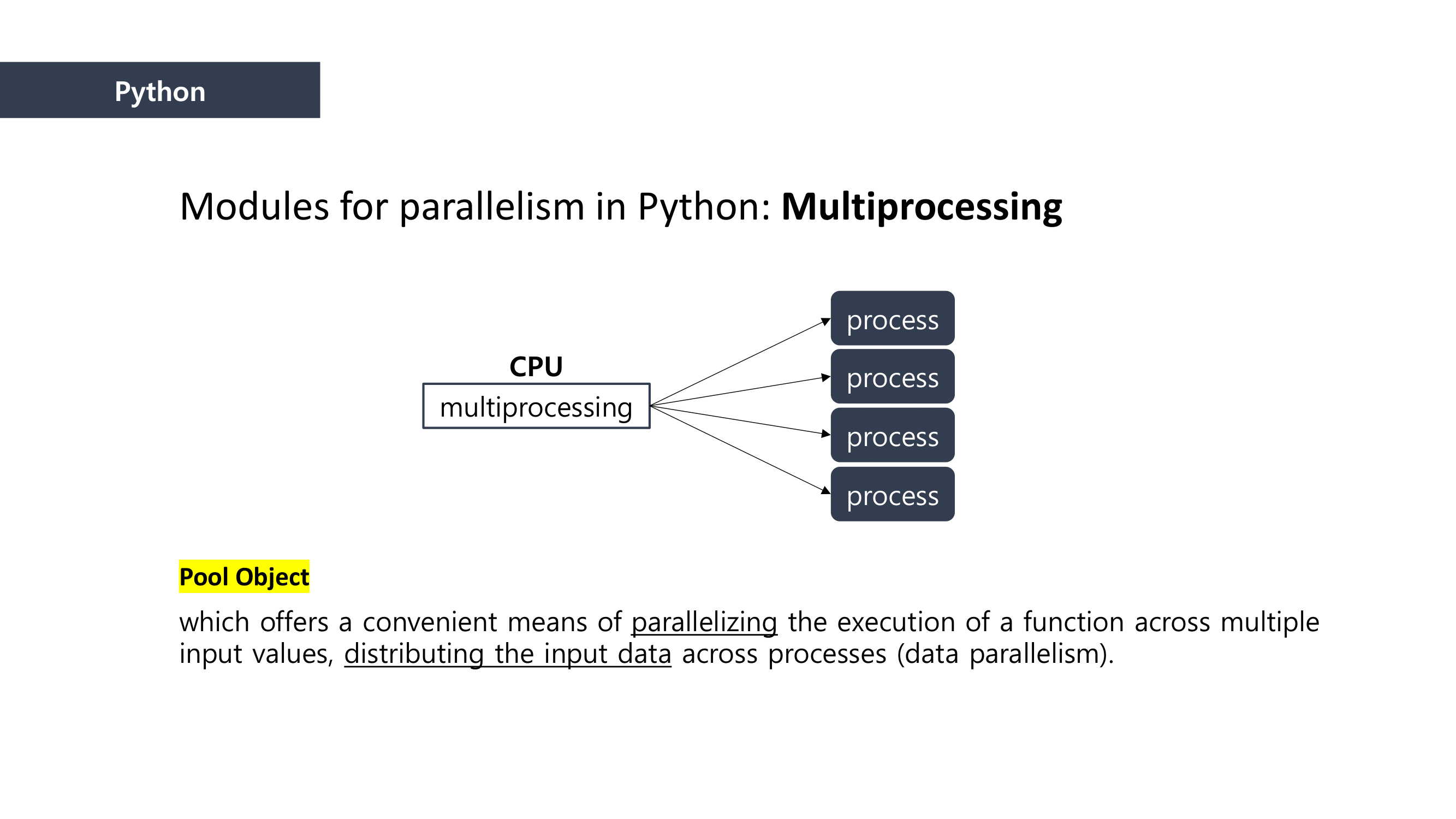
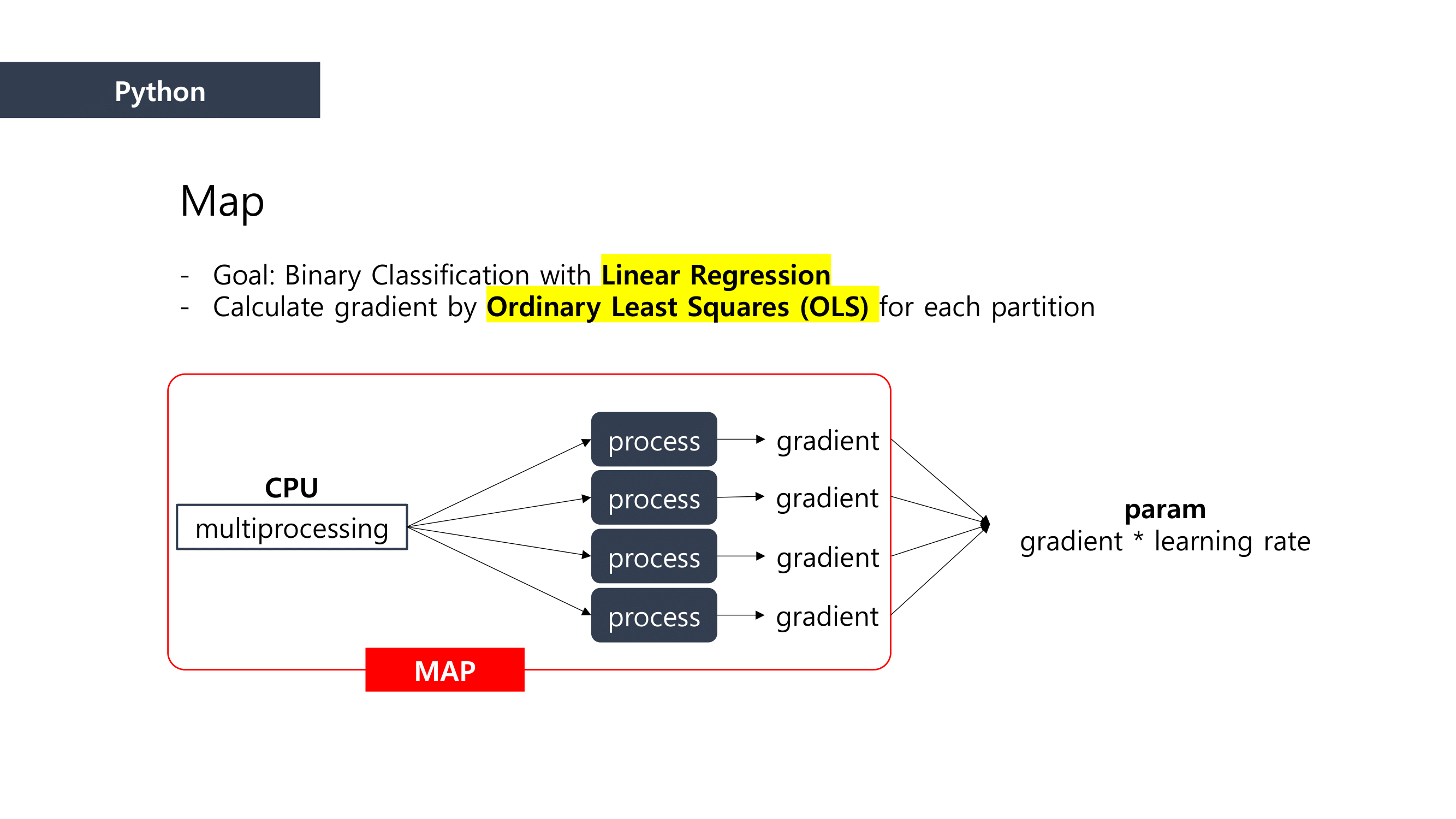
We used Linear Regression as a Machine Learning method to predict the loan defaulter. This is why the Ordinary least squares formula was applied to the mapping process. We calclutate the gradients in this process.